KI wird Ihre Web Component nicht refactoren
KI-Tools erweitern lokale Muster schnell. Sie liefern jedoch nicht das Design-Urteilsvermögen, um Komplexität zu redu...
9 Min. Lesezeit
25.06.2026, Von Stephan Schwab

Git Worktrees machen KI-Coding nicht parallel. Integration bleibt sequenziell — daran ändert sich nichts, egal wie viele Verzeichnisse man gleichzeitig geöffnet hat. Was Worktrees wirklich liefern, ist ein wegwerfbarer Wirkungsradius: ein Ort, an dem der Agent erzeugen, überschreiben und sich gelegentlich blamieren kann, ohne die Linie zu berühren, auf die man sich verlässt. Das Modell ist weniger wichtig, als die Leute denken. Das Harness — welche Dateien der Agent sehen kann, welche Werkzeuge er aufrufen darf, in welcher Sandbox er lebt — ist der Ort, an dem der praktische Unterschied entsteht. Ein Worktree macht das Harness ehrlich, indem er den vom Agenten erzeugten Chaos aus dem Integrations-Checkout heraushält, bis man entscheidet, dass er es verdient hat zu überleben. Eine Regel hält das Ganze davon ab, sich still in einen versteckten Branch-Workflow zu verwandeln: Erstelle einen Worktree nur für Arbeit, die du bereit bist wegzuwerfen.
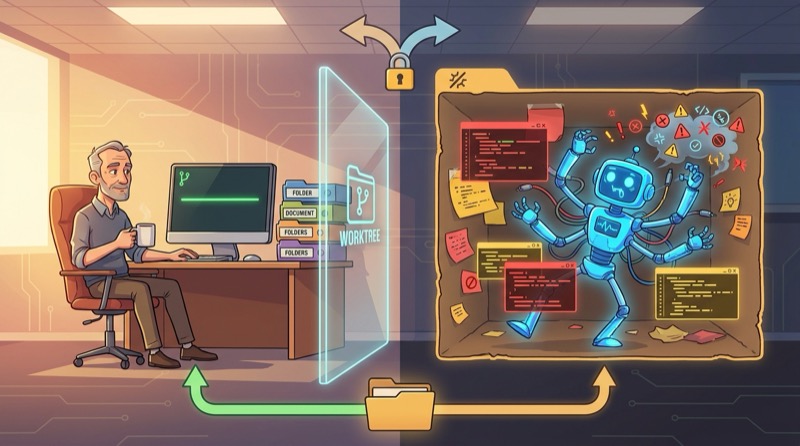
Die erste Reaktion auf Git Worktrees ist oft vernünftig: Ist das nur ein Branch mit besserem Marketing?
Nicht ganz. Ein Branch ist eine Entwicklungslinie. Ein Worktree ist ein weiterer Ordner, der auf einem Branch ausgecheckt ist. Gleiches Repository. Gleiche Historie. Anderes Verzeichnis.
Das bringt etwas Konkretes:
myapp/ main
myapp-spike-auth/ spike/auth-cleanup
myapp-docs/ wait/docs-cleanup
Das ist nützlich. Es ist aber weitaus weniger magisch, als viele behaupten.
Worktrees lösen kein Koordinationsproblem. Sie lösen ein einfacheres und sehr reales Ärgernis: Sie wollen ein weiteres sauberes Checkout, ohne unfertige Arbeit zu stashen, ständig Branches hin- und herzuwechseln oder Ihr Hauptarbeitsverzeichnis wie einen Tatort aussehen zu lassen.
Die Leute reden oft so, als wären GitHub Copilot, Claude Code, Codex, OpenCode, Pi und der Rest magische Wesen mit grundlegend unterschiedlichen Superkräften. Das ist der falsche Rahmen.
Das Modell ist wichtig. Natürlich ist es das. Aber das meiste von dem, was man im Alltag erlebt, ist nicht “das Modell” isoliert. Es ist der Stack drum herum.
Drei Teile bilden das, was landläufig “die KI” genannt wird:
Diese Unterscheidung ist wichtig, weil die Agenten-Schleife zwischen GitHub Copilot und Claude Code meistens nur Klempnerarbeit ist: Wie viele Schritte vergehen, bis er stoppt, wie er das Kontextfenster verwaltet, wie er bei Fehlern einen neuen Versuch startet. Die Unterschiede in der Umgebung (Harness) sind größer und erklären das meiste von dem gefühlten Abstand zwischen den Tools. Unterschiedliche Tool-Definitionen. Unterschiedliche Datei-Lese-Strategien. Unterschiedliche System-Prompts. Unterschiedliches Sandboxing. Unterschiedliche Leitplanken.
GitHub Copilot im Agenten-Modus, Claude Code, OpenCode, Codex CLI, Pi und ähnliche Werkzeuge kombinieren diese Teile alle unterschiedlich. Manche haben bessere Planungs-Schleifen. Manche injizieren nützlicheren Repository-Kontext. Manche haben einen stärkeren Terminal-Workflow. Manche sind in ein besseres Editing-Erlebnis eingepackt. Manche haben einfach weniger Leitplanken und fühlen sich daher mutiger an, bis zu dem Moment, in dem sie etwas Wichtiges zerschießen.
Es stimmt also meistens nicht, dass “Claude das für mich erledigt”, während “Copilot das nicht kann.” In der Regel vergleicht man ein stärkeres Harness, eine andere Kontext-Strategie und eine leicht abweichende Agenten-Schleife – und ist nicht Zeuge einer göttlichen Intervention eines Markennamens. Die Token-Vorhersage des Modells ist notwendig, aber nicht ausreichend. Die Umgebung ist der Ort, an dem die praktische Magie lebt oder stirbt.
Git Worktrees wurden viel interessanter, als KI-Coding-Agenten den Raum betraten. Nicht, weil der Agent jetzt in irgendeinem tiefgründigen Sinne parallel entwickelt. Sondern weil der Agent schnell, produktiv und oft genauso schlampig ist, wie ein übermütiger Praktikant schlampig wäre.
Das verändert den Wert von Isolation.
Ein zweiter Worktree gibt dem Agenten einen Ort, um Code zu generieren, Code neu zu schreiben, über das Ziel hinauszuschießen und sich gelegentlich zu blamieren, ohne das Checkout zu verschmutzen, das als Integrationslinie dient.
Hier kommt das Harness ins Spiel. Ein Worktree ist nicht nur ein Git-Trick. In der Praxis wird er Teil des Harness. Er gibt dem Agenten eine separate Dateisystem-Ansicht, einen separaten Dirty-Status, einen separaten Explosionsradius. Gleiches Repository. Gleiche Historie. Geringere Wahrscheinlichkeit, dass ein weggeworfenes Experiment die Linie kontaminiert, die einem eigentlich wichtig ist.
Steckt man dasselbe Modell in ein schwaches Harness, wirkt es ungeschickt. Steckt man ein nur mittelmäßiges Modell in ein starkes Harness mit den richtigen Dateien, den richtigen Tools, den richtigen Tests und einem temporären Worktree, sprechen die Leute plötzlich davon, als wäre es über Nacht intelligent geworden.
Lassen Sie den Agenten woanders Chaos anrichten. Bringen Sie nur die Teile zurück, die es verdienen, zu überleben.
Das ist der eigentliche praktische Gewinn. Spikes, riskante Refactorings, alternative Implementierungen, Dokumentations-Aufräumarbeiten, das Hinzufügen von Tests und Upgrade-Experimente werden alle einfacher, wenn der Explosionsradius in einem anderen Ordner bleibt.
Die verlockende Idee ist diese: Wenn ich mehrere Worktrees habe, kann ich parallele Entwicklung betreiben.
Sie können parallel editieren. Dieser Teil ist billig.
Sie kommen jedoch nicht um sequenzielles Verstehen, Reviewen, Testen und Integrieren herum. Ein Stream wird zum nächsten stabilen Zustand der Codebasis. Dann der nächste. Das Repository verschmilzt nicht wie von Zauberhand zu einem kohärenten Produkt, nur weil zwei Verzeichnisse gleichzeitig existieren.
Selbst als Solo-Entwickler bleibt die Einschränkung langweilig und nicht verhandelbar: Integration ist immer noch sequenziell.
Sie müssen immer noch entscheiden, was gut ist, was gefährlich ist, was Nacharbeit erfordert und was ohne Zeremonie gelöscht werden sollte.
Das spielt bei KI-gestütztem Programmieren eine noch größere Rolle, weil das Tool größere Änderungs-Sets schneller erzeugen kann, als Ihr Urteilsvermögen sie sicher aufnehmen kann.
Für Solo-Entwicklung auf dem Main-Branch (Trunk-based Development) ist der normale Ablauf immer noch der richtige: Arbeiten an Main, eine kleine Scheibe beenden, testen, committen, pushen.
Nichts an Worktrees ändert diese Disziplin. Es gibt Ihnen lediglich einen anderen Ort, um wegwerfbare Arbeit zu erledigen, während die Main-Linie stabil, grün und release-fähig bleibt.
Das bedeutet, das gesunde mentale Modell sieht so aus:
In dem Moment, in dem der Worktree aufhört, wegwerfbar zu sein, driftet er ab in das alte Feature-Branch-Chaos, nur mit besserer Ergonomie.
Eine gute Einsatzregel ist brutal einfach: Erstellen Sie einen Worktree nur für Arbeit, die Sie bereit sind, wegzuwerfen. Diese Regel hält das Ganze ehrlich.
Wenn sich der Branch im Worktree wertvoll, politisch oder zu groß anfühlt, um ihn wegzuwerfen, hat er seinen Nutzen bereits überlebt. Jetzt schützen Sie nicht mehr die Trunk-based Development. Sie ersetzen sie klammheimlich durch einen versteckten Branch-Workflow und hoffen, dass die zukünftige Version von Ihnen Spaß am Merge haben wird.
Nützliche Lebensdauer: Minuten oder Stunden. Schlechtes Zeichen: Tage oder Wochen.
Ein temporärer Worktree sollte schnell gemerged, ge-cherry-pickt, manuell kopiert oder gelöscht werden. Andernfalls häuft er Integrationsschulden an, während er Produktivität vortäuscht.
| Anwendungsfall | Eignung | Grund |
|---|---|---|
| Spike oder Experiment | Gut | Leicht zu verwerfen |
| Riskantes Agenten-Refactoring | Gut | Hält Main sauber |
| Vergleich zweier Implementierungen | Gut | Separate Ordner erleichtern den Vergleich |
| Dokumentation aufräumen | Gut | Wenig Konflikte |
| Tests für unzusammenhängenden Code | Gut | Meistens unabhängig |
| Einen Bug untersuchen | Gut | Man kann frei inspizieren |
| Abhängigkeits-Upgrade-Experiment | Gut | Riskant, aber isoliert |
| Lang laufender Feature-Branch | Schlecht | Kämpft gegen Trunk-based Development |
| Zwei Agenten, die dasselbe Modul bearbeiten | Schlecht | Review- und Merge-Schmerz taucht schnell auf |
| Paralleles Schema- und Service-Refactoring | Schlecht | Versteckte Kopplung kassiert irgendwann ihre Gebühr |
Die Trennlinie ist simpel. Wenn die Arbeit billig wegzuwerfen und später leicht zu integrieren ist, hilft ein Worktree. Wenn die Arbeit tief mit dem gekoppelt ist, was sich bereits im Main ändert, macht ein zweites Verzeichnis sie nicht sicherer.
Der beste Anwendungsfall ist nicht: “Ich möchte zwei Features auf einmal entwickeln.”
Der bessere Anwendungsfall ist dieser: Während der Agent arbeitet oder Tests in einem Checkout laufen, nutze ich ein anderes Checkout für kleine, unabhängige Arbeiten. Das macht Worktrees ideal für Leerlauf-Lücken, die sonst verschwendet würden.
Gute Wartezeit-Aufgaben:
Schlechte Wartezeit-Aufgaben:
Hier geht es nicht darum, gleichzeitiges Programmieren zu maximieren. Es geht darum, den Flow beizubehalten, ohne zusätzliche Aufräumarbeit zu produzieren.
In diesem Solo-Workflow ist die GitHub CLI nützlich, aber sekundär.
Sie hilft, wenn die Arbeit GitHub-gehostete Koordination statt lokaler Code-Isolation berührt. Issues, Workflow-Runs, Releases und ähnliche Repository-Hausarbeiten passen gut rein. Pull Requests spielen eine geringere Rolle, wenn man sie nicht benutzt.
Nützliche Befehle könnten sein:
gh issue list
gh issue view 123
gh run list
gh run watch
Hilfreich? Ja. Zentraler Produktivitätshebel? Nein.
Der größere Hebel ist, ein weiteres Arbeitsverzeichnis zu haben, damit lokale Aktivität nicht blockiert, nur weil ein Checkout gerade beschäftigt, “dirty” oder mitten in einem Experiment ist.
Normales Checkout:
repo/ main
Temporärer Worktree:
repo-wait/ wait/small-task
Dann halten Sie den Flow absichtlich langweilig:
Der wichtige Teil ist nicht, wie viele Verzeichnisse existieren. Der wichtige Teil ist, dass immer nur ein Stream auf einmal zum nächsten stabilen Trunk-Zustand wird.
Git Worktrees lösen dies: Ich brauche ein weiteres sauberes Checkout ohne Stashen oder Branch-Wechsel.
Sie lösen nicht dies: Ich möchte, dass sich mehrere Entwicklungsströme sicher von selbst integrieren.
Diese zweite Fantasie kollabiert immer noch beim Kontakt mit der Realität. Jemand muss das Ergebnis überprüfen, die Tests ausführen und die Entscheidung treffen. Wenn Sie dieser Jemand sind, ist der Engpass nicht verschwunden. Er hat sich nur vom Tippen zum Urteilen verlagert.
Beim KI-gestützten Programmieren sind Git Worktrees kein Weg, um Disziplin zu vermeiden. Sie sind ein Weg, um Disziplin zu wahren, während man dem Agenten ein sichereres Harness gibt.
Das ist die weniger magische und nützlichere Wahrheit. Das Beeindruckende ist selten die Marke auf der Verpackung. Es ist die Kombination aus Modellqualität, Agenten-Verhalten und Harness-Design. Worktrees helfen, weil sie das Harness verbessern. Sie machen Urteilsvermögen nicht parallel, und sie retten kein schlampiges Denken. Sie geben der Maschine lediglich eine Teststrecke, damit Ihr Trunk nicht zu einer wird.
Sprechen wir über Ihre reale Situation. Möchten Sie Auslieferung beschleunigen, technische Blockaden beseitigen oder prüfen, ob eine Idee mehr Investition verdient? Ich höre Ihren Kontext und gebe 1-2 praktische Empfehlungen. Ohne Pitch, ohne Verpflichtung. Vertraulich und direkt.
Zusammenarbeit beginnenTelenovelas zeigen, was wir in Kundengesprächen nicht sagen können. Das Drama ist gesteigert, aber die Muster sind real.
 Der Preis der Geschwindigkeit
Der Preis der Geschwindigkeit
Mit dem Start von Q3 steigt der Druck auf das Team, das Turniersystem zu liefern. Anton drückt auf eine schnelle, unsaubere Umsetzung der Matchmaki...
 Niemals einen Lauf verpasst
Niemals einen Lauf verpasst
Zwei Särge sinken in den nassen Boden von Ohio, und Graham Whitaker erbt das Unternehmen, das sein Vater mit COBOL und sturem Stolz aufgebaut hat. ...
In Ihr Team eingebettet als aktiver Beitragsleister, der Delivery-Reibung verringert und wichtige Arbeit sauber voranbringt.
Technische Einschätzungen im Peer-Stil vor weitreichenden Entscheidungen; reduziert früh Architektur- und Produktrisiken.
Funktionsfähige Software früher bei echten Nutzern. Wirkung messen und auf Evidenz statt Annahmen anpassen.
Hochwertige, wartbare Software. Kurzfristige Verstärkung, die langfristig Kompetenz im eigenen Team hinterlässt.
Suchen Sie etwas Bestimmtes? Stöbern Sie nach Datum oder Thema.
Ein erfahrener Entwickler für dein Team
Unser Developer Advocate schreibt produktiven Code mit deinem Team, verbessert die Pipeline und beschleunigt die Auslieferung. 60-70% Coding, 30-40% Coaching. Ein Teamkollege auf Zeit, der vom ersten Tag an liefert.