La IA no refactorizará tu Web Component
La IA extiende patrones locales rápidamente. No aporta de manera confiable el criterio de diseño para reducir la comp...
10 min de lectura
25.06.2026, Por Stephan Schwab

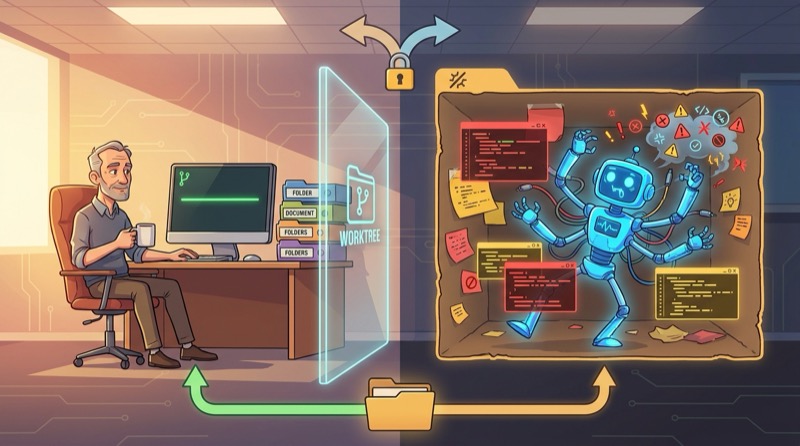
Los Git Worktrees no hacen que la codificación con IA sea paralela. La integración sigue siendo secuencial, y eso no cambia sin importar cuántos directorios tengas abiertos a la vez. Lo que los worktrees realmente te dan es un radio de explosión desechable: un lugar donde el agente puede generar, sobreescribir y ocasionalmente hacer el ridículo sin tocar la línea de la que dependes. El modelo importa menos de lo que la gente cree. El harness — qué archivos puede ver el agente, qué herramientas puede invocar, en qué sandbox vive — es donde reside la diferencia práctica. Un worktree hace que el harness sea honesto al mantener el desorden generado por el agente fuera de tu checkout de integración hasta que decidas que merece sobrevivir. Una regla evita que todo esto se convierta silenciosamente en un flujo de ramas ocultas: crea un worktree solo para trabajo que estés dispuesto a descartar.
La primera reacción a los Git Worktrees suele ser razonable: ¿es esto solo un branch con mejor marketing?
No exactamente. Un branch es una línea de desarrollo. Un worktree es otra carpeta en la que se ha hecho checkout de un branch. Mismo repositorio. Misma historia. Directorio distinto.
Eso le da algo concreto:
myapp/ main
myapp-spike-auth/ spike/auth-cleanup
myapp-docs/ wait/docs-cleanup
Eso es útil. También es mucho menos mágico de lo que la gente hace sonar.
Los worktrees no resuelven la coordinación. Resuelven una molestia más simple y muy real: usted quiere otro checkout limpio sin tener que hacer stash de trabajo a medio terminar, cambiar de branches de ida y vuelta, o hacer que su directorio de trabajo principal parezca la escena de un crimen.
La gente sigue hablando como si GitHub Copilot, Claude Code, Codex, OpenCode, Pi y los demás fueran seres mágicos con superpoderes fundamentalmente diferentes. Ese es un marco equivocado.
El modelo importa. Por supuesto que sí. Pero gran parte de lo que la gente experimenta en el día a día no es “el modelo” de manera aislada. Es el stack que hay a su alrededor.
Tres piezas componen lo que usted llama “la IA”:
Esa distinción es importante porque el bucle del agente entre GitHub Copilot y Claude Code es en su mayoría solo fontanería: cuántos pasos da antes de detenerse, cómo maneja la ventana de contexto, cómo reintenta tras un fallo. Las diferencias en el entorno (harness) son más grandes y explican la mayor parte de la brecha percibida entre las herramientas. Diferentes definiciones de herramientas. Diferentes estrategias de lectura de archivos. Diferentes system prompts. Diferente sandboxing. Diferentes barandillas (guardrails).
GitHub Copilot en modo agente, Claude Code, OpenCode, Codex CLI, Pi y herramientas similares combinan todas estas piezas de forma diferente. Algunas tienen mejores bucles de planificación. Algunas inyectan un contexto de repositorio más útil. Algunas tienen un flujo de terminal más fuerte. Algunas están envueltas en una mejor experiencia de edición. Algunas simplemente tienen menos barandillas y por lo tanto se sienten más audaces hasta que rompen algo importante.
Así que no, normalmente no es cierto que “Claude lo hace por mí” mientras que “Copilot no puede”. Casi siempre se está comparando un entorno más fuerte, una estrategia de contexto diferente y un bucle de agente ligeramente distinto; no se está presenciando la intervención divina de una marca comercial. La predicción de tokens del modelo es necesaria pero no suficiente. El entorno es donde la magia práctica vive o muere.
Los Git Worktrees se volvieron mucho más interesantes una vez que los agentes de código de IA entraron en escena. No porque el agente ahora esté desarrollando en paralelo en un sentido profundo. Sino porque el agente es rápido, prolífico y a menudo descuidado exactamente de la misma manera que un pasante con exceso de confianza sería descuidado.
Eso cambia el valor del aislamiento.
Un segundo worktree le da al agente un lugar para generar código, reescribir código, extralimitarse y ocasionalmente avergonzarse a sí mismo sin contaminar el checkout que usted está usando como su línea de integración.
Ahí es donde entra el entorno (harness). Un worktree no es solo un truco de Git. En la práctica se convierte en parte del entorno. Le da al agente una vista de sistema de archivos separada, un estado sucio separado, un radio de explosión separado. Mismo repositorio. Misma historia. Menor probabilidad de que un experimento desechable contamine la línea que realmente le importa.
Ponga el mismo modelo en un entorno débil y se sentirá torpe. Ponga un modelo apenas decente en un entorno fuerte con los archivos correctos, las herramientas correctas, las pruebas correctas y un worktree desechable, y de repente la gente hablará como si se hubiera vuelto inteligente de la noche a la mañana.
Deje que el agente haga un desastre en otro lugar. Traiga de vuelta solo las partes que merezcan sobrevivir.
Esa es la verdadera ganancia práctica. Picos de desarrollo (spikes), refactors riesgosos, implementaciones alternativas, limpieza de documentación, adición de pruebas y experimentos de actualización se vuelven más fáciles cuando el radio de explosión se mantiene en otra carpeta.
La idea seductora es esta: si tengo múltiples worktrees, puedo hacer desarrollo en paralelo.
Usted puede hacer edición en paralelo. Esa parte es barata.
Pero todavía no puede esquivar la comprensión, la revisión, las pruebas y la integración de manera secuencial. Un stream se convierte en el siguiente estado estable del código. Luego lo hace el siguiente. El repositorio no se fusiona solo en un producto coherente solo porque existan dos directorios al mismo tiempo.
Incluso como desarrollador en solitario, la restricción sigue siendo aburrida y no negociable: la integración sigue siendo secuencial.
Todavía tiene que decidir qué es bueno, qué es peligroso, qué necesita retrabajo y qué debería borrarse sin ceremonia.
Eso importa aún más con la programación asistida por IA, porque la herramienta puede crear conjuntos de cambios más grandes más rápido de lo que su juicio puede absorber de forma segura.
Para el desarrollo basado en trunk en solitario (trunk-based development), el flujo normal sigue siendo el correcto: trabajar en main, terminar una porción pequeña, probarla, hacer commit y push.
Nada de los worktrees cambia esa disciplina. Solo le da otro lugar para hacer trabajo desechable mientras la línea principal se mantiene estable, en verde y lista para lanzarse.
Eso significa que el modelo mental saludable se ve así:
En el momento en que el worktree deja de ser desechable, comienza a desviarse hacia el viejo desastre de los feature branches, solo que con mejor ergonomía.
Una buena regla operativa es brutalmente simple: solo cree un worktree para el trabajo que esté dispuesto a tirar a la basura. Esa regla mantiene todo el asunto honesto.
Si el branch dentro del worktree se siente valioso, político o demasiado grande para dejarlo caer, ya ha sobrevivido a su utilidad. Ahora usted no está protegiendo el trunk-based development. Lo está reemplazando silenciosamente por un flujo de trabajo de branches ocultos, y esperando que la versión futura de usted mismo disfrute de hacer el merge.
Vida útil recomendada: minutos u horas. Mala señal: días o semanas.
Un worktree temporal debería fusionarse (merge), hacerle cherry-pick, copiarse manualmente o borrarse rápidamente. De lo contrario, empieza a acumular deuda de integración mientras finge ser productividad.
| Caso de uso | Ajuste | Razón |
|---|---|---|
| Spike o experimento | Bueno | Fácil de descartar |
| Refactor de agente riesgoso | Bueno | Mantiene main limpio |
| Comparar dos implementaciones | Bueno | Carpetas separadas facilitan la comparación |
| Limpieza de documentación | Bueno | Bajo conflicto |
| Agregar tests a código no relacionado | Bueno | Usualmente independiente |
| Investigar un bug | Bueno | Se puede inspeccionar libremente |
| Experimento de actualización de dependencias | Bueno | Riesgoso pero aislado |
| Feature branch de larga duración | Pobre | Lucha contra trunk-based development |
| Dos agentes editando el mismo módulo | Pobre | El dolor de revisión y merge aparece rápido |
| Refactor paralelo de esquema y servicio | Pobre | El acoplamiento oculto eventualmente cobra su cuota |
La línea divisoria es simple. Si el trabajo es barato de tirar a la basura y fácil de integrar más tarde, un worktree ayuda. Si el trabajo está profundamente acoplado a lo que ya está cambiando en main, un segundo directorio no lo hace más seguro.
El mejor caso de uso no es “quiero desarrollar dos características a la vez”.
El mejor caso de uso es este: mientras el agente trabaja o los tests corren en un checkout, uso otro checkout para hacer un trabajo independiente y pequeño. Eso hace que los worktrees sean ideales para esos bolsillos inactivos de tiempo que de otro modo se desperdiciarían.
Buenas tareas para el tiempo de espera:
Malas tareas para el tiempo de espera:
Esto no se trata de maximizar el código simultáneo. Se trata de mantener el flujo sin fabricar trabajo adicional de limpieza.
En este flujo de trabajo en solitario, la CLI de GitHub es útil, pero secundaria.
Ayuda cuando el trabajo toca la coordinación hospedada en GitHub en lugar de la aislación de código local. Los issues, los workflow runs, los releases y la limpieza de repositorio encajan bien. Los pull requests importan menos cuando no los está usando.
Comandos útiles podrían ser:
gh issue list
gh issue view 123
gh run list
gh run watch
¿Útil? Sí. ¿Palanca central de productividad? No.
La mayor palanca es tener otro directorio de trabajo para que la actividad local no se detenga solo porque un checkout esté ocupado, “sucio” (dirty) o en medio de un experimento.
Checkout normal:
repo/ main
Worktree temporal:
repo-wait/ wait/small-task
Luego mantenga el flujo aburrido a propósito:
La parte importante no es cuántos directorios existen. La parte importante es que solo un stream se convierte en el siguiente estado estable de trunk a la vez.
Los Git Worktrees resuelven esto: Necesito otro checkout limpio sin hacer stash o cambiar branches.
No resuelven esto: Quiero que múltiples flujos de desarrollo se integren de forma segura por sí solos.
Esa segunda fantasía todavía colapsa en el contacto con la realidad. Alguien tiene que revisar el resultado, correr los tests y tomar la decisión. Si ese alguien es usted, entonces la restricción no desapareció. Solo se movió de escribir código a usar su juicio.
Con la programación asistida por IA, los Git Worktrees no son una forma de evitar la disciplina. Son una forma de preservar la disciplina al tiempo que se le da al agente un entorno (harness) más seguro.
Esa es la verdad menos mágica y más útil. La parte impresionante rara vez es la marca en la caja. Es la combinación de la calidad del modelo, el comportamiento del agente y el diseño del entorno. Los worktrees ayudan porque mejoran ese entorno. No vuelven el juicio paralelo, ni rescatan el pensamiento descuidado. Simplemente le dan a la máquina una pista de pruebas para que su trunk no se convierta en una.
Hablemos de tu situación real. ¿Quieres acelerar la entrega, quitar bloqueos técnicos o validar si una idea merece más inversión? Escucho tu contexto y te doy 1-2 recomendaciones prácticas. Sin compromiso ni discurso comercial. Confidencial y directo.
Empecemos a trabajar juntosLas telenovelas muestran lo que no podemos decir en reuniones con clientes. El drama está intensificado, pero los patrones son reales.
 El Costo de la Velocidad
El Costo de la Velocidad
Con el arranque de Q3, la presión por entregar el sistema de torneos sube de golpe. Anton empuja una implementación rápida y sucia de la UI de matc...
 Nunca Falló una Ejecución
Nunca Falló una Ejecución
Dos ataúdes descienden en la tierra mojada de Ohio, y Graham Whitaker hereda la compañía que su padre construyó con COBOL y orgullo testarudo. Sema...
Integrado en tu equipo como colaborador activo, reduce la fricción de entrega y ayuda a que el trabajo importante avance con claridad.
Evaluaciones técnicas antes de decisiones de gran alcance para reducir riesgos de arquitectura y producto.
Llevar software funcional a usuarios reales más pronto. Medir impacto y adaptar basado en evidencia.
Software de alta calidad y fácil de mantener. Refuerzo temporal que deja capacidad duradera en tu propio equipo.
¿Buscas algo específico? Explora por fecha o tema.
Un desarrollador experimentado para tu equipo
Nuestro Developer Advocate programa código productivo con tu equipo, mejora el pipeline y acelera la entrega. 60-70% código, 30-40% coaching. Un compañero de equipo temporal que entrega desde el primer día.